Porting a Python Limit Orderbook to Rust
For the past year, I have been running automated mean-reversion strategies on crypto markets, with all of the code written in python. Recently I became interested in market making and created a few new bots to make markets on centralized exchanges. To run these strategies, I create an in-memory orderbook which updates in real-time using websockets and mirrors the orderbook on the exchange. I also sometimes use this orderbook for backtesting.
The python orderbook which I had originally written is good enough for back-testing, but is too slow for real-time market situations. Even trying to convert a large chunk of code into cython/pypy didn’t speed up the code enough.

I have recently been looking into Rust, and decided to port the entire orderbook to Rust, just because I couldn’t squeeze any more performance out of my python code and C++ seemed too boring.
What is a Limit Order Book?
For each asset, there is a single Order book. It consists of orders grouped at price levels.
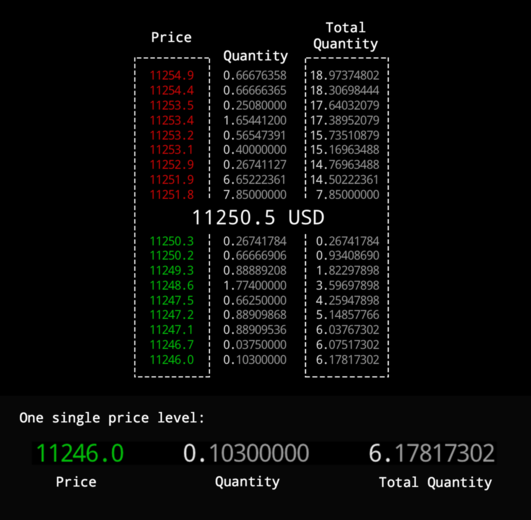
Typical Orderbook
At each price level, an order in this book specifies the quantity and Side i.e. whether to buy or sell. The top of the book is where you’ll find the highest bid and lowest ask prices. We need easy access to these, since they represent the best buy/sell price we get if we place a market order.
Price time matching
For almost all crypto markets, the orders are matched using FIFO semantics; matching priority is first price, and then time. Thus, if you are a market participant, you are rewarded for offering the best price and being early.
Implementation
Now that we know what an orderbook is, we can begin with a simple implementation. First, we will define a few enums:
|
|
Order
An Order is simply a struct with 2 fields: id and qty. Notice that we do not store the price within the order struct.
|
|
We can infer everything else about the order from its position in the book.
Halfbooks
The orderbook itself consists of 2 “half” orderbooks, one each for the bid and ask side. Each halfbook consists of a vector of double-ended queues where each deque represents a single price level.
The pricemap is a BTreeMap with the key as the price and value as the index into the price level vector. This allows for instant O(1) lookup of each price level.
|
|
Using this structure, we can lookup the order with a simple linear search at the price level.
Since most updates happen near the inside of the book, we could have gotten away with using a vector instead of a deque, however the deque allows for faster deletions (remove(i) runs in O(min(i, n-i)) and is not as cache “unfriendly” as a linked list.
Just to be sure, I tried the vector version as well, and the overall speedup was insignificant.
Price and timestamp
Since our orderbook is private, we do not need to store a timestamp and we can deduce which order came first simply from it’s position in the deque.
Notice that each price is a u64, we multiply each price with an appropriate quantity-step size such that it becomes a u64. Thus, if the bitcoin price is 50689.4321, we will multiply it by 10000 and store it as 506894321. This to avoid strings and floating point calculations as they tend to be slow and/or unreliable.
Orderbook
We can now combine all these elements to get our orderbook:
|
|
I chose to store the BBO (best bid/offer) separately as it allows me to calculate the spread instantly, although it does require extra code to keep updated.
Also storing the order_loc hashmap allows us to skip some computation in complex order types. It also allows us to cancel orders in ~10 lines of code:
|
|
Adding/Matching orders:
When we receive a new limit order, we simply check if it crosses the orderbook, delete orders appropriately if it does and update the best bid offer.
|
|
For more details you can take a look at the code on github.
Performance
This simple order book can match a single order in around ~13 μs whereas the python version took around ~120 μs.
In my live systems I am seeing a consistent 10-15x performance improvement for each order compared to the python version. The memory impact is more significant, python consumed ~40x the memory of the rust program.
This is a flamegraph for creating/matching and cancelling 100,000 orders each.
Click on the image to interact with it
Is this fast enough to beat the largest market makers on the BTC and ETH markets? Probably not.
But it is fast enough (and profitable!) for my specific needs.
Calling into rust from python code
To call into this rust code from my python codebase, I am using PyO3, which wasn’t too difficult to integrate, but it definitely felt a bit tedious. I will create a future post detailing this process.
Another option here was to use rust-cpython, but I haven’t tried it.
Further Reading
For a greater understanding on orderbooks and liquidity, I highly recommend reading Trading and Exchanges by Larry Harris. It is a bit dated, but most of the concepts are still applicable to today’s markets.
Good resources on implementing orderbooks are here here and here.